

Den kinesiske AI-industrien har tatt et betydelig sprang. To nye modeller - Moonshot AIs Kimi K2.5 og Alibabas Qwen3-Max - slår nå amerikanske modeller fra OpenAI, Anthropic og Google på flere viktige benchmarks.
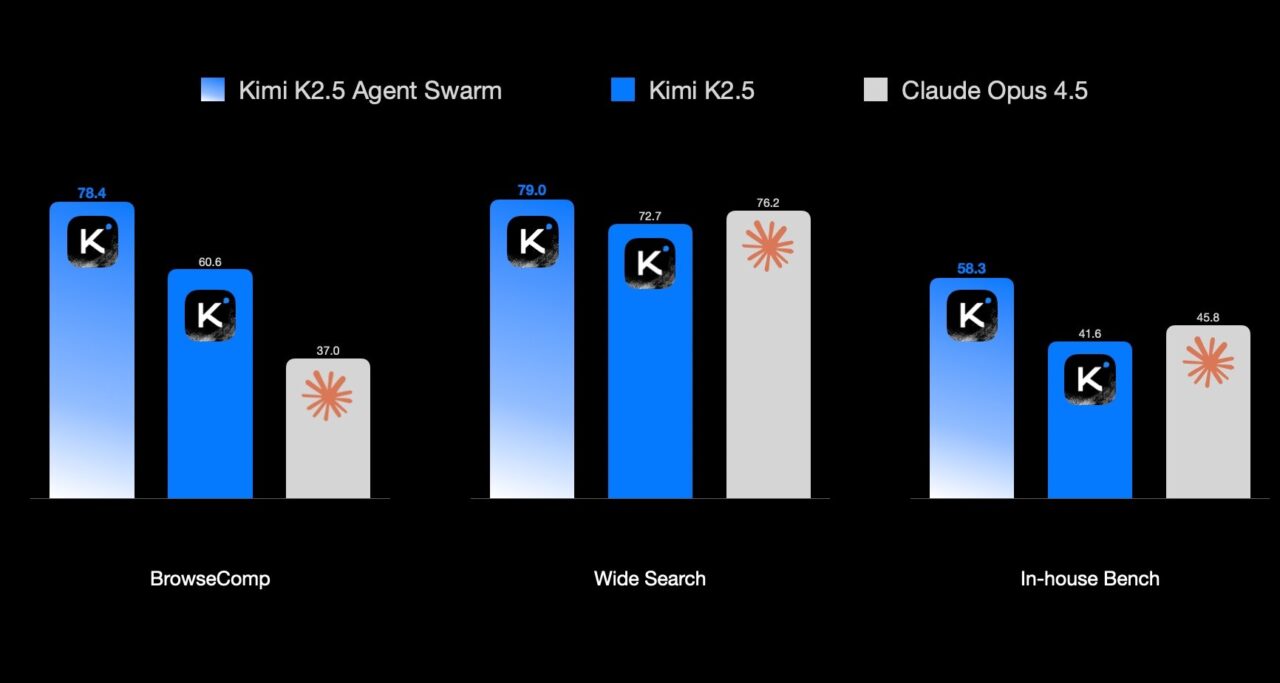
Kimi K2.5 knuser på agentiske oppgaver
Moonshots nye modell scorer 51,8 prosent på HLE-Full-testen med verktøybruk, mot Claude Opus 4.5 sine 47,1 prosent. På SWE-Bench, som tester evnen til å fikse bugs i ekte kodeprosjekter, oppnår Kimi K2.5 hele 80,9 prosent.
Det mest imponerende er hastigheten: Kimis «Agent Swarm»-funksjon kan kjøre 100 AI-agenter parallelt og er 4,5 ganger raskere enn konkurrentene.
Alibaba scorer 100 prosent på mattetest
Qwen3-Max fra Alibaba oppnådde perfekt score på AIME 2025, en krevende matematikk-konkurranse. Til sammenligning klarte GPT-4o bare 26,7 prosent på samme test.
Billigere og åpent tilgjengelig
Begge modellene er open source og betydelig billigere å kjøre. Kimi K2.5 koster 76 prosent mindre enn Claude Opus 4.5. Ni av ti beste open source-modeller er nå kinesiske.
Nvidia-sjef Jensen Huang har kalt Qwen, DeepSeek og Kimi «de beste open reasoning-modellene i verden». Det er en bemerkelsesverdig innrømmelse, spesielt i lys av amerikanske eksportrestriksjoner på AI-chips til Kina.
Et vendepunkt i det globale AI-kappløpet
Resultatene markerer et vendepunkt i det globale AI-kappløpet. Kinesiske selskaper viser at de kan konkurrere på toppnivå - og i noen tilfeller lede - til tross for begrensninger på tilgang til avansert maskinvare.


Kommentarer0